Bij Cashfeed gebruiken we AI in productie voor zaken die rechtstreeks van invloed zijn op onze klanten: het extraheren van gegevens uit facturen, het classificeren van documenten en het matchen van banktransacties met facturen. Fouten maken bij die matches is kostbaar. Foute koppelingen betekenen foute boekhouding, extra handmatig werk en verloren vertrouwen. Daarom brengen we geen AI updates naar productie op hoop van zege. We sturen ze alleen uit wanneer onze eigen evaluatietool zegt dat ze goed genoeg zijn.
Dit bericht gaat over hoe dat in de praktijk werkt, met de transactiematcher als het belangrijkste voorbeeld. Hetzelfde idee geldt voor onze extractie- en classificatiemodellen: we beschouwen evaluatie als een eersteklas systeem, niet als een nagedachte. Het gaat erom waarom we een intern AI-evaluatie pipeline hebben gebouwd in plaats van alleen op onderbuikgevoel te vertrouwen, en hoe het onze transactiematcher betrouwbaar maakt.
Het probleem: AI die "goed aanvoelt" is niet genoeg
Het is verleidelijk om AI te beoordelen door een paar voorbeelden te proberen en te zien of het "goed aanvoelt". Dat is nuttig voor verkenning, maar het is niet genoeg om:
Vol vertrouwen te verzenden: Je weet nooit of de laatste aanpassing één geval heeft opgelost en drie andere heeft verbroken.
Rechvaardig te vergelijken: "Deze uitvoering zag er beter uit" is geen maatstaf. Je hebt elke keer dezelfde testset en dezelfde scoring nodig.
Systematisch te verbeteren: Zonder een herhaalbare benchmark ben je aan het optimaliseren in het duister.
We hadden een manier nodig om onze echte AI-pijplijnen te draaien op vaste scenario's, de output te vergelijken met feiten en een duidelijke slaag/falen en score te krijgen. Dus hebben we een evaluatiesysteem gebouwd dat precies dat doet.
Wat ons evaluatiesysteem doet
Ons evaluatiesysteem is ingebouwd in het product en wordt elke dag door het team gebruikt. In het kort:
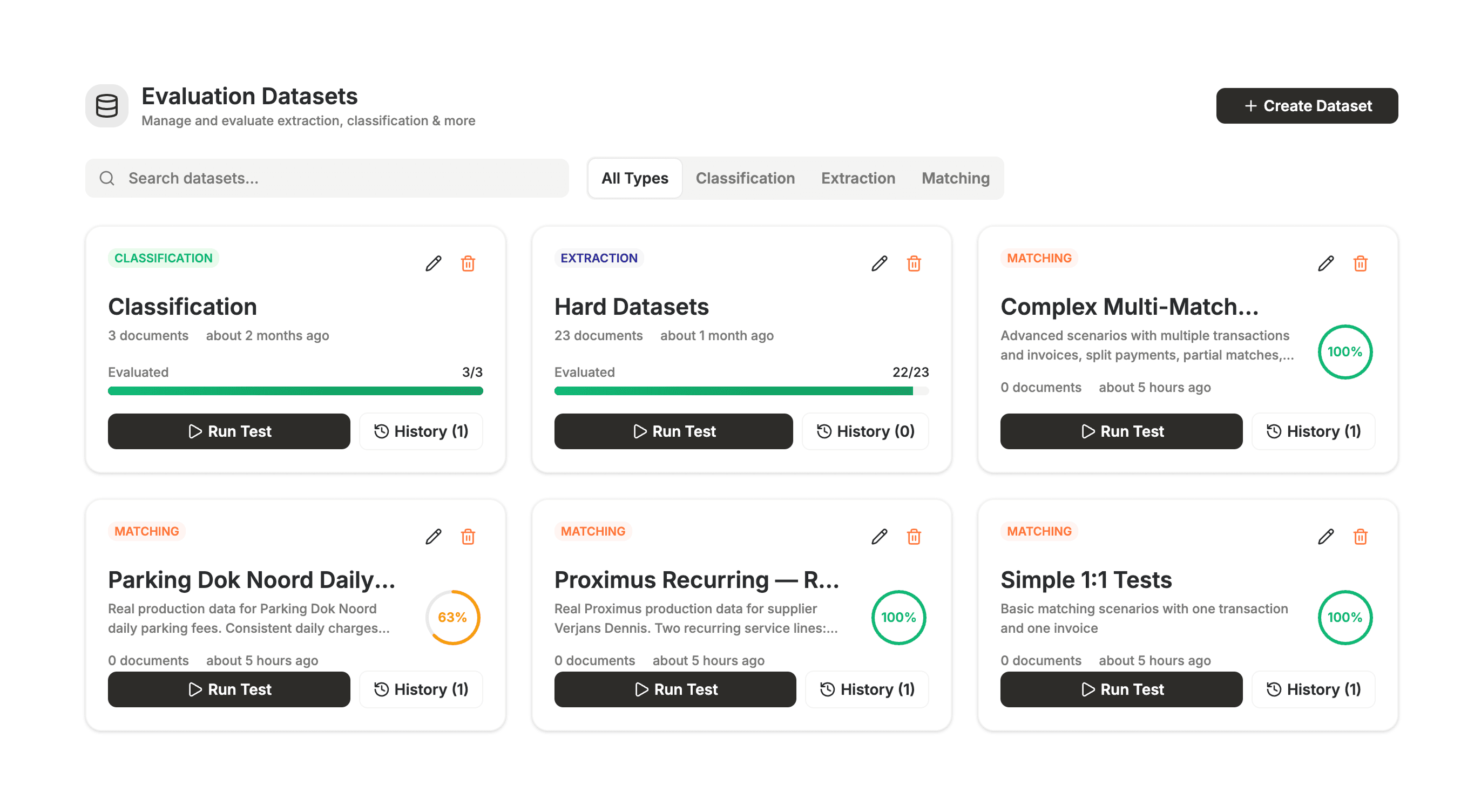
Datasets: We definiëren evaluatiedatasets op type: extractie, classificatie of matching. Elke dataset is een zorgvuldig samengesteld set invoer en de "juiste" antwoorden die we verwachten.
Testuitvoeringen: Een testuitvoering voert de echte AI-pijplijn (dezelfde codepad als de productie) uit op elk scenario in de dataset.
Scores: We vergelijken de output van het model met de grondwaarheid en krijgen een duidelijke slaag/falen en score per scenario.
Geschiedenis: Elke uitvoering wordt opgeslagen. We kunnen zien of een wijziging het model in de loop van de tijd heeft verbeterd of verslechterd.
Geen aparte "evaluatie-script" die van de productie afdrijft. De code die in evaluatie draait is de code die voor klanten draait. Als de evaluatie slaagt, testen we hetzelfde gedrag dat we verzenden.
Waarom we het zelf hebben gebouwd
Er zijn tal van evaluatietools en -kaders, voor LLM's, voor RAG, voor algemene "AI-apps". We hebben ernaar gekeken en we hebben nog steeds gekozen om onze eigen te bouwen. De reden is simpel: onze case is te specifiek.
Onze pijplijnen zijn domeinspecifiek: ze hebben te maken met facturen, banktransacties, boekhoudkundige semantiek en regelgevingseisen. Wat "juist" voor ons betekent is niet alleen "het model zei iets redelijks", het is "deze transactie was correct gekoppeld aan deze factuur," "dit veld was binnen toleranties geëxtraheerd," "dit document was correct geclassificeerd." De invoer, uitvoer en succescriteria zijn aan ons product gekoppeld. Algemene evaluatietools zijn gebouwd voor algemene prompts en algemene metrics. Ze weten niets over onze datavormen, onze multi-stap pijplijnen, of ons onderscheid tussen automatisch toegepaste matches en door gebruikers bevestigde suggesties. Het inpluggen van onze stromen in een kant-en-klaar kader zou hebben betekend dat we ofwel het hulpmiddel ofwel onze logica moesten buigen en we zouden nog steeds onze eigen scenario's en scoring moeten definiëren. Dus hebben we een evaluatielaag gebouwd die onze domein spreekt, onze echte code draait en resultaten in ons systeem opslaat. We hebben volledige controle en nul mismatch tussen "wat we evalueren" en "wat we verzenden."
De transactiematcher in evaluatie
De transactiematcher is een goed voorbeeld. Zijn taak: gegeven banktransacties en facturen, beslissen welke transactie welke factuur betaalt. We gaan hier niet in op onze matchinglogica, dat is product en IP. Wat belangrijk is voor deze post is hoe we het evalueren.
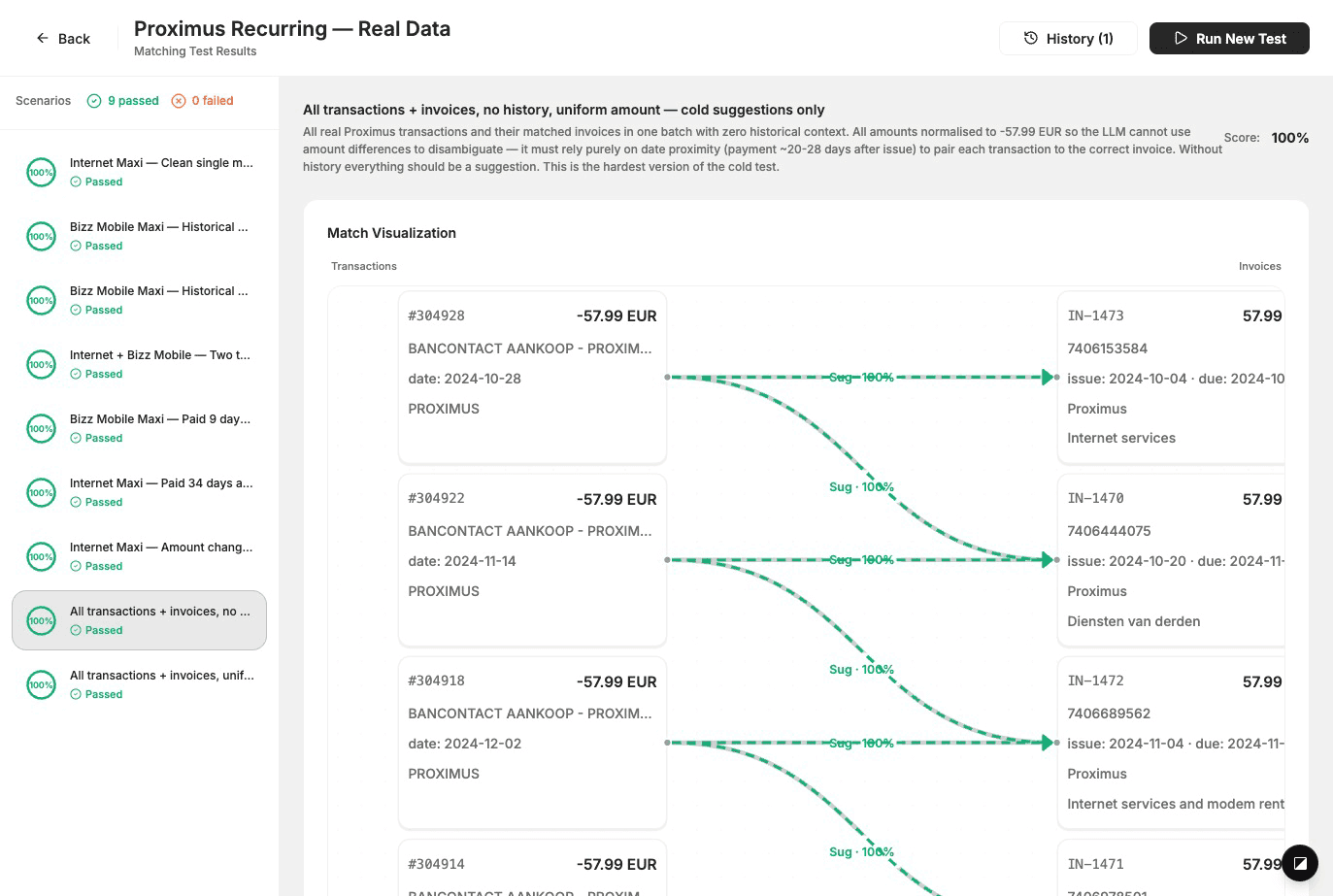
We onderhouden matching datasets: sets van scenario's met realistische transacties en facturen, plus grondwaarheid (welke paren moeten worden gematched, en of ze automatisch zijn toegepast of voorgesteld). We draaien de daadwerkelijke matcher op elk scenario, vergelijken de output met de grondwaarheid en scoren. Scenario's zijn opgebouwd uit geanonimiseerde gegevens die lijken op productie, zodat we de randgevallen testen die daadwerkelijk voorkomen voor klanten. Elke wijziging aan de matcher wordt gevalideerd tegen deze datasets voordat het de deur uitgaat. Dat is hoe we de kwaliteit hoog houden zonder bloot te stellen hoe we de matching zelf doen.
Wanneer we een test uitvoeren, zien we precies hoe de matcher zich op elk scenario heeft gedragen: welke transactie-factuurparen het heeft voorgesteld, hoe dat zich verhoudt tot wat we verwachtten, en een score.
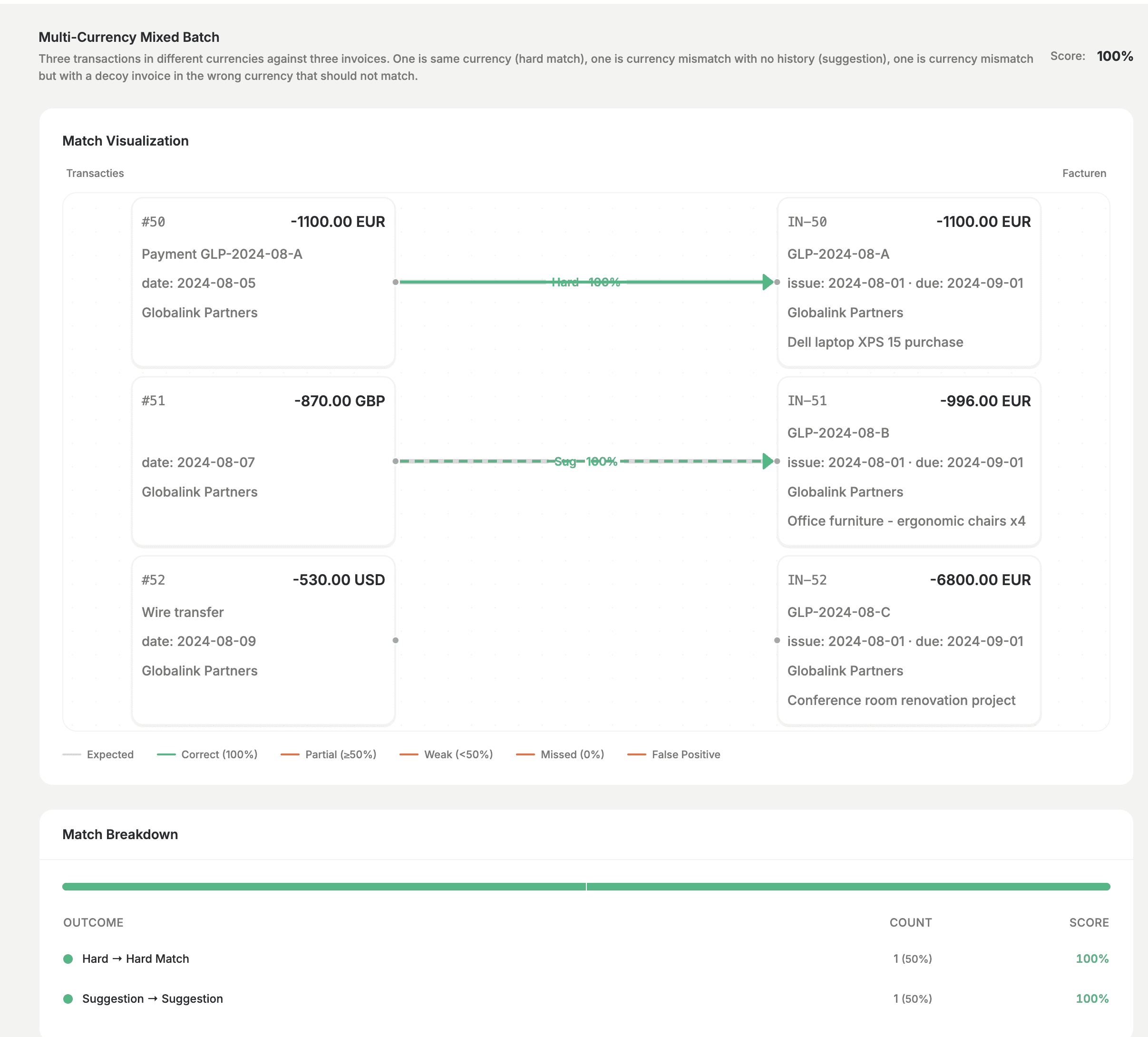
We testen ook moeilijkere gevallen: bijvoorbeeld meerdere valuta in één batch, of situaties waarin het model correct enkele transacties ongematcht moet laten. Het goed krijgen van die gevallen en het resultaat in de tool zien is hoe we valse positieven vermijden en de lat hoog houden.
Waarom dit onze software betrouwbaar maakt
Regressieve veiligheid: Voordat we een wijziging aan de matcher (of aan extractie/classificatie) samenvoegen, draaien we de relevante evaluatie. Als de uitvoering faalt of de score daalt, verzenden we niet totdat we begrijpen waarom en dit fixen.
Duidelijke verbetercriteria: We kunnen zeggen “deze wijziging verbeterde de score op onze matching benchmark” in plaats van “het voelt beter aan.”
Vertrouwen in productie: Dezelfde codepad wordt gebruikt in evaluatie en in productie, dus wanneer we zeggen “de matcher is geëvalueerd,” bedoelen we hetgene dat voor klanten draait.
Snellere iteratie: We kunnen prompt- en logische wijzigingen proberen en binnen enkele minuten een numeriek resultaat krijgen, zonder handmatig tientallen gevallen opnieuw te controleren.
We beweren niet dat we AI-evaluatie in het algemeen hebben opgelost. We hebben onze evaluatie voor onze pijplijnen opgelost: dezelfde code, zorgvuldig samengestelde scenario's en een strikte definitie van “slaag.” Dat is de standaard waaraan we ons houden als een product dat met echte boekhoudgegevens omgaat.
Wat is de volgende stap
We blijven scenario's toevoegen aan onze matching (en andere) datasets terwijl we nieuwe randgevallen ontdekken in de productie of vanuit de ondersteuning. We breiden ook dezelfde evaluatiediscipline uit naar andere AI-functies. Het doel blijft hetzelfde: de modellen op een meetbare manier verbeteren, en nooit een regressie verzenden zonder het te weten.
Als je AI in kritieke workflows bouwt, vooral in fintech of boekhouding, dan heeft het vroeg investeren in je eigen evaluatie pipeline zijn vruchten afgeworpen. Dat is wat ons in staat stelt om snel te bewegen zonder dingen te breken.
— Wij zijn René Van Der Schueren en Jonathan Callewaert (CTO). We hebben de Transactiematcher bij Cashfeed gebouwd. In dit bericht delen we hoe we een van de meest frustrerende problemen in financiële workflows hebben aangepakt: het matchen van facturen met banktransacties.








