Chez Cashfeed, nous utilisons l'IA en production pour des choses qui affectent directement les livres de nos clients : extraction de données à partir de factures, classification de documents, et correspondance des transactions bancaires avec les factures. Se tromper dans ces correspondances coûte cher. Des liens erronés signifient une comptabilité erronée, un travail manuel supplémentaire et une perte de confiance. Ainsi, nous ne déployons pas les changements d'IA en espérant le meilleur. Nous ne les expédions que lorsque notre propre outil d'évaluation dit qu'ils sont suffisamment bons.
Cet article porte sur le fonctionnement de tout cela en pratique, avec le correspondant de transaction comme exemple principal. La même idée s'applique à nos modèles d'extraction et de classification : nous considérons l'évaluation comme un système de première classe, et non comme une réflexion tardive. Il s'agit de la raison pour laquelle nous avons construit un pipeline d'évaluation IA en interne au lieu de compter sur un instinct et comment cela maintient notre correspondant de transaction honnête.
Le problème : l'IA qui semble correcte n'est pas suffisante
Il est tentant de juger l'IA en essayant quelques exemples et en voyant si cela « semble » correct. C'est utile pour l'exploration, mais ce n'est pas suffisant pour :
Expédier avec confiance : Vous ne savez jamais si le dernier changement de prompt a corrigé un cas et en a cassé trois autres.
Comparer équitablement : « Cette exécution semblait meilleure » n'est pas une métrique. Vous avez besoin du même ensemble de test, du même score, à chaque fois.
Améliorer systématiquement : Sans un benchmark répétable, vous optimisez dans le flou.
Nous avions besoin d'une manière d'exécuter nos véritables pipelines IA sur des scénarios fixes, de comparer les résultats à la vérité terrain et d'obtenir un pass/fail clair et un score. Nous avons donc construit un système d'évaluation qui fait exactement cela.
Ce que fait notre système d'évaluation
Notre système d'évaluation est intégré au produit et utilisé par l'équipe chaque jour. En résumé :
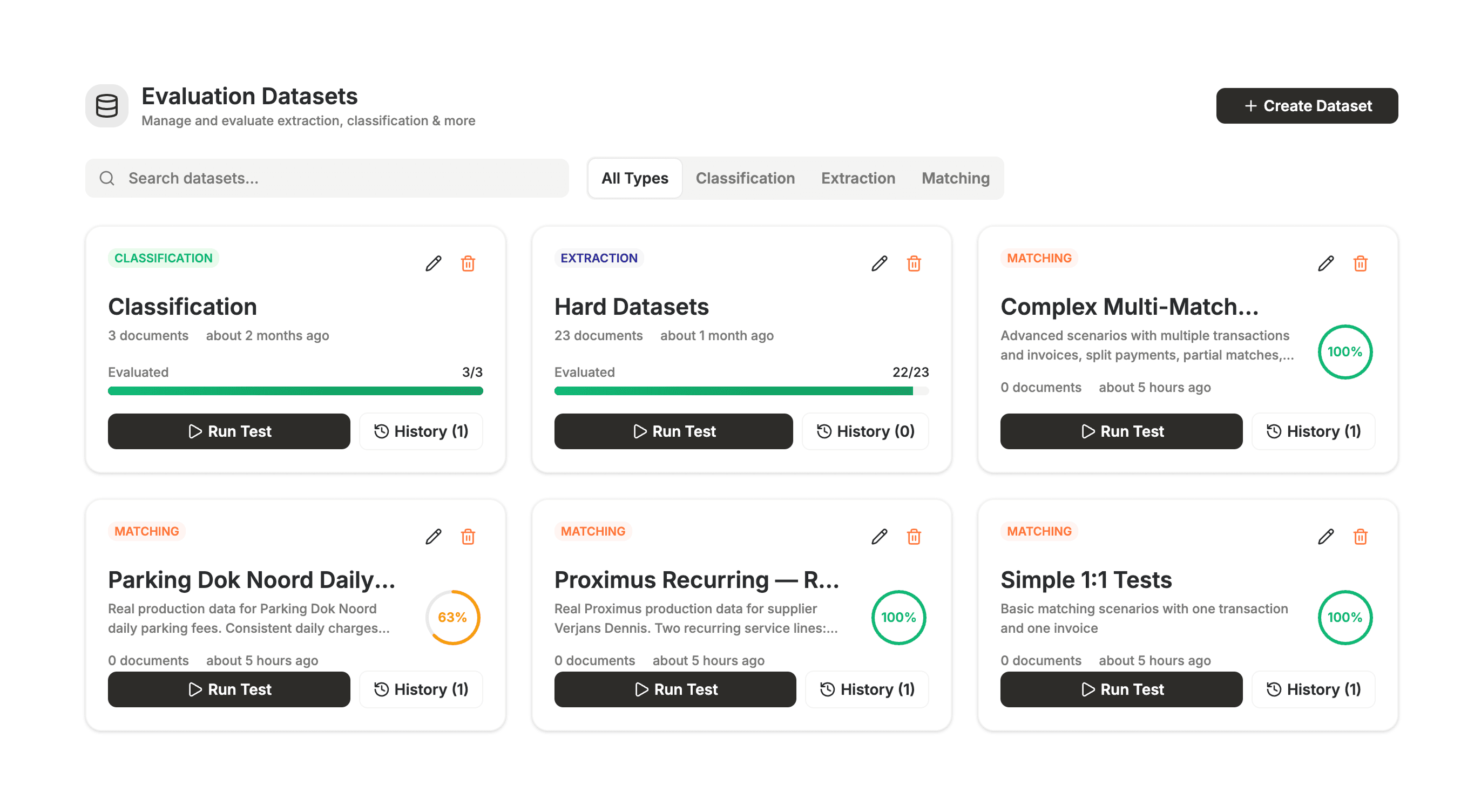
Données : Nous définissons les ensembles de données d'évaluation par type : extraction, classification ou correspondance. Chaque ensemble de données est un ensemble curaté d'entrées et des « bonnes » réponses que nous attendons.
Exécutions de test : Une exécution de test exécute le véritable pipeline IA (même chemin de code que la production) sur chaque scénario de l'ensemble de données.
Notation : Nous comparons la sortie du modèle à la vérité terrain et obtenons un pass/fail clair ainsi qu'un score par scénario.
Historique : Chaque exécution est stockée. Nous pouvons voir si un changement a amélioré ou régressé le modèle au fil du temps.
Pas de « script d'évaluation » séparé qui s'éloigne de la production. Le code qui s'exécute dans l'évaluation est le code qui s'exécute pour les clients. Si l'évaluation est réussie, nous testons le même comportement que nous expédions.
Pourquoi nous l'avons construit nous-mêmes
Il existe de nombreux outils et cadres d'évaluation pour les LLM, pour le RAG, pour les « applications IA » génériques. Nous les avons examinés, et nous avons tout de même choisi de construire le nôtre. La raison est simple : notre cas est trop spécifique.
Nos pipelines sont spécifiques au domaine : ils traitent des factures, des transactions bancaires, des sémantiques comptables et des attentes réglementaires. Ce que signifie « correct » pour nous n'est pas juste « le modèle a dit quelque chose de raisonnable », c'est « cette transaction a été correctement liée à cette facture », « ce champ a été extrait dans les limites tolérées », « ce document a été classé dans le bon type ». Les entrées, les sorties et les critères de succès sont liés à notre produit. Les outils d'évaluation génériques sont construits pour des prompts génériques et des métriques génériques. Ils ne connaissent pas nos formes de données, nos pipelines à plusieurs étapes, ou notre distinction entre les correspondances appliquées automatiquement et les suggestions confirmées par l'utilisateur. Brancher nos flux dans un cadre prêt à l'emploi aurait signifié plier soit l'outil soit notre logique et nous aurions tout de même eu besoin de définir nos propres scénarios et scores. Donc, nous avons construit une couche d'évaluation qui parle notre domaine, exécute notre code réel et stocke les résultats dans notre système. Nous obtenons un contrôle total et aucun écart entre « ce que nous évaluons » et « ce que nous expédions ».
Le correspondant de transaction en évaluation
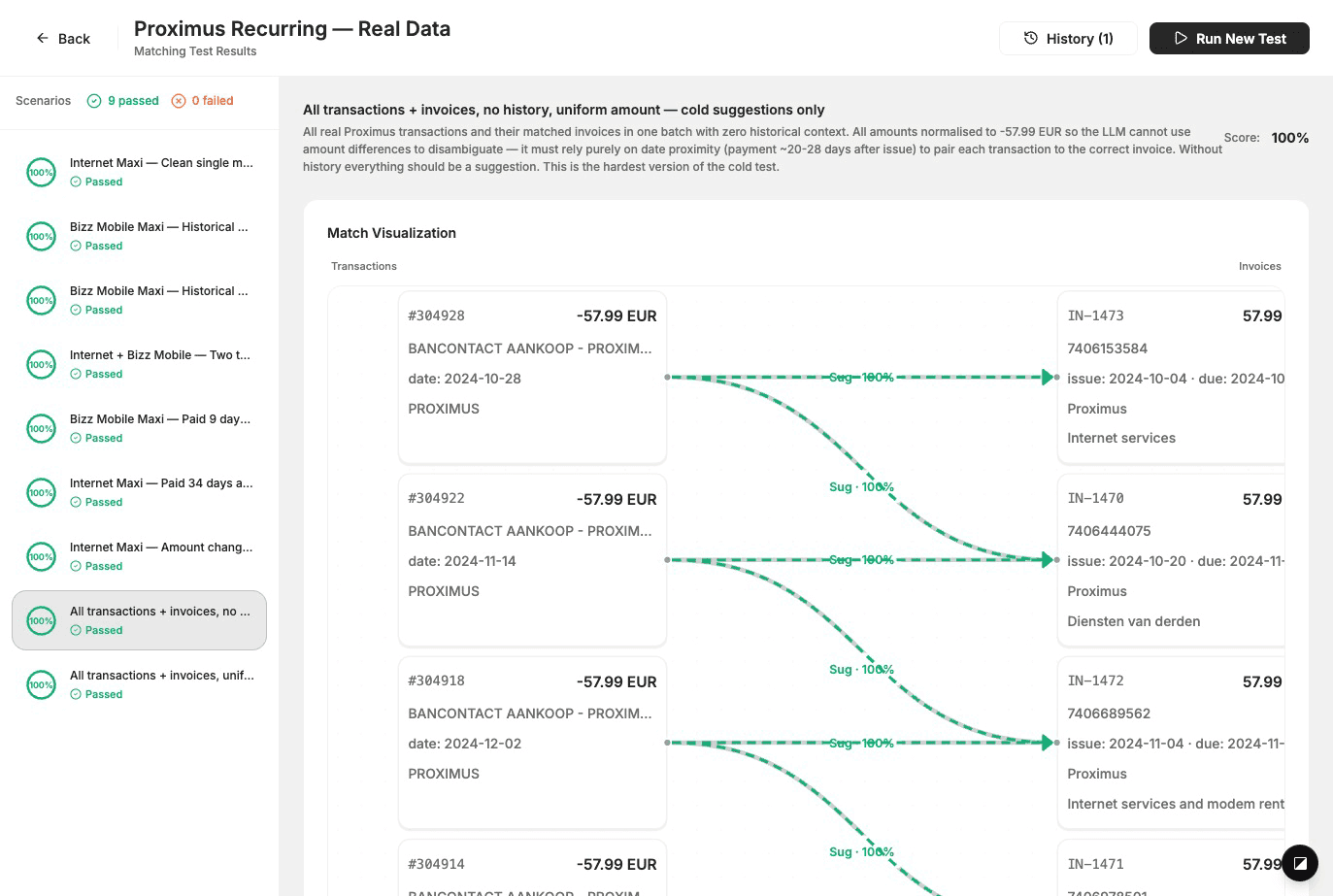
Le correspondant de transaction est un bon exemple. Son rôle : étant donné des transactions bancaires et des factures, décider quelle transaction paie quelle facture. Nous ne nous attardons pas ici sur notre logique de correspondance, c'est un produit et une propriété intellectuelle. Ce qui est important pour cet article, c'est comment nous l'évaluons.
Nous maintenons des ensembles de données de correspondance : des ensembles de scénarios avec des transactions et des factures proches de la réalité, plus la vérité terrain (quels paires doivent être associées, et si elles sont appliquées automatiquement ou suggérées). Nous exécutons le véritable correspondant sur chaque scénario, comparons la sortie à la vérité terrain, et notons. Les scénarios sont construits à partir de données anonymisées ressemblant à la production afin que nous puissions tester les cas extrêmes qui se présentent réellement aux clients. Chaque modification du correspondant est validée par rapport à ces ensembles de données avant d'être mise à disposition. C'est comme cela que nous maintenons un niveau de qualité élevé sans exposer notre méthode de correspondance.
Lorsque nous exécutons un test, nous voyons exactement comment le correspondant s'est comporté dans chaque scénario : quelles paires transaction–facture il a proposées, comment cela se compare à nos attentes, et un score.
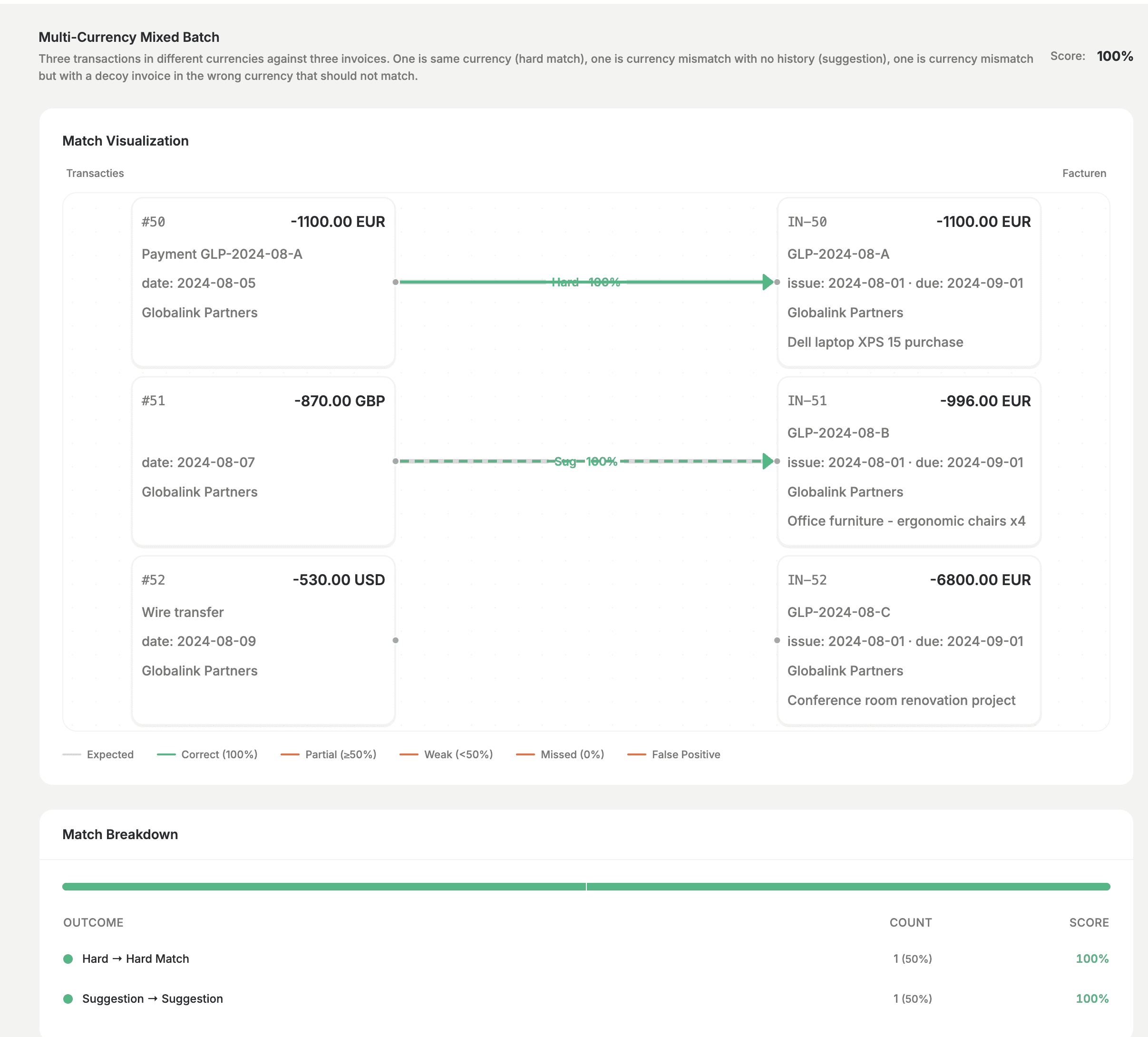
Nous testons également des cas plus complexes, par exemple des devises multiples dans un lot, ou des situations où le modèle devrait correctement laisser certaines transactions non assorties. Obtenir des résultats corrects, et les voir dans l'outil, est comment nous évitons les faux positifs et maintenons le niveau élevé.
Pourquoi cela nous rend plus matures
Sécurité contre la régression : Avant de fusionner un changement dans le correspondant (ou dans l'extraction/classification), nous exécutons l'évaluation pertinente. Si l'exécution échoue ou si le score diminue, nous n'expédions pas tant que nous n'avons pas compris pourquoi et corrigé le problème.
Critères d'amélioration clairs : Nous pouvons dire « ce changement a amélioré le score sur notre référence de correspondance » au lieu de « cela semble meilleur ».
Confiance en production : Le même chemin de code est utilisé dans l'évaluation et en production, donc lorsque nous disons « le correspondant est évalué », nous voulons dire le produit qui est utilisé par les clients.
Itération plus rapide : Nous pouvons essayer des changements de prompt et de logique et obtenir un résultat numérique en quelques minutes, sans devoir vérifier manuellement des dizaines de cas.
Nous ne prétendons pas avoir résolu l'évaluation de l'IA en général. Nous avons résolu notre évaluation pour nos pipelines : même code, scénarios curatés et définition stricte de ce qu'est








