At Cashfeed we use AI in production for things that directly affect our customers’ books: extracting data from invoices, classifying documents, and matching bank transactions to invoices. Getting those matches wrong is costly. Wrong links mean wrong accounting, extra manual work, and lost trust. So we don’t ship AI changes on a hope and a prayer. We ship them only when our own evaluation tool says they’re good enough.
This post is about how that works in practice, with the transaction matcher as the main example. The same idea applies to our extraction and classification models: we treat evaluation as a first-class system, not an afterthought. It's about why we've built an in-house AI evaluation pipeline instead of relying on gut feeling and how it keeps our transaction matcher honest.
The problem: AI that “feels” right isn’t enough
It’s tempting to judge AI by trying a few examples and seeing if it “feels” right. That’s useful for exploration, but it’s not enough to:
Ship confidently: You never know if the last prompt change fixed one case and broke three others.
Compare fairly: “This run looked better” isn’t a metric. You need the same test set, the same scoring, every time.
Improve systematically: Without a repeatable benchmark, you’re optimizing in the dark.
We needed a way to run our real AI pipelines on fixed scenarios, compare the output to ground truth, and get a clear pass/fail and score. So we built an evaluation system that does exactly that.
What our evaluation system does
Our eval system is built into the product and used by the team every day. In short:
Datasets: We define evaluation datasets by type: extraction, classification, or matching. Each dataset is a curated set of inputs and the “right” answers we expect.
Test runs: A test run executes the real AI pipeline (same code path as production) on every scenario in the dataset.
Scoring: We compare model output to ground truth and get a clear pass/fail and score per scenario.
History: Every run is stored. We can see whether a change improved or regressed the model over time.
No separate “eval script” that drifts from production. The code that runs in eval is the code that runs for customers. If the eval passes, we’re testing the same behaviour we ship.
Why we built it ourselves
There are plenty of evaluation tools and frameworks out there, for LLMs, for RAG, for generic “AI apps.” We looked at them, and we still chose to build our own. The reason is simple: our case is too specific.
Our pipelines are domain-specific: they deal with invoices, bank transactions, accounting semantics, and regulatory expectations. What “correct” means for us isn’t just “the model said something reasonable”, it’s “this transaction was correctly linked to this invoice,” “this field was extracted within tolerance,” “this document was classified to the right type.” The inputs, outputs, and success criteria are tied to our product. Generic eval tools are built for generic prompts and generic metrics. They don’t know about our data shapes, our multi-step pipelines, or our distinction between auto-applied matches and user-confirmed suggestions. Plugging our flows into an off-the-shelf framework would have meant bending either the tool or our logic and we’d still need to define our own scenarios and scoring. So we built an eval layer that speaks our domain, runs our real code, and stores results in our system. We get full control and zero mismatch between “what we evaluate” and “what we ship.”
The transaction matcher in eval
The transaction matcher is a good example. Its job: given bank transactions and invoices, decide which transaction pays which invoice. We don’t go into our matching logic here, that’s product and IP. What matters for this post is how we evaluate it.
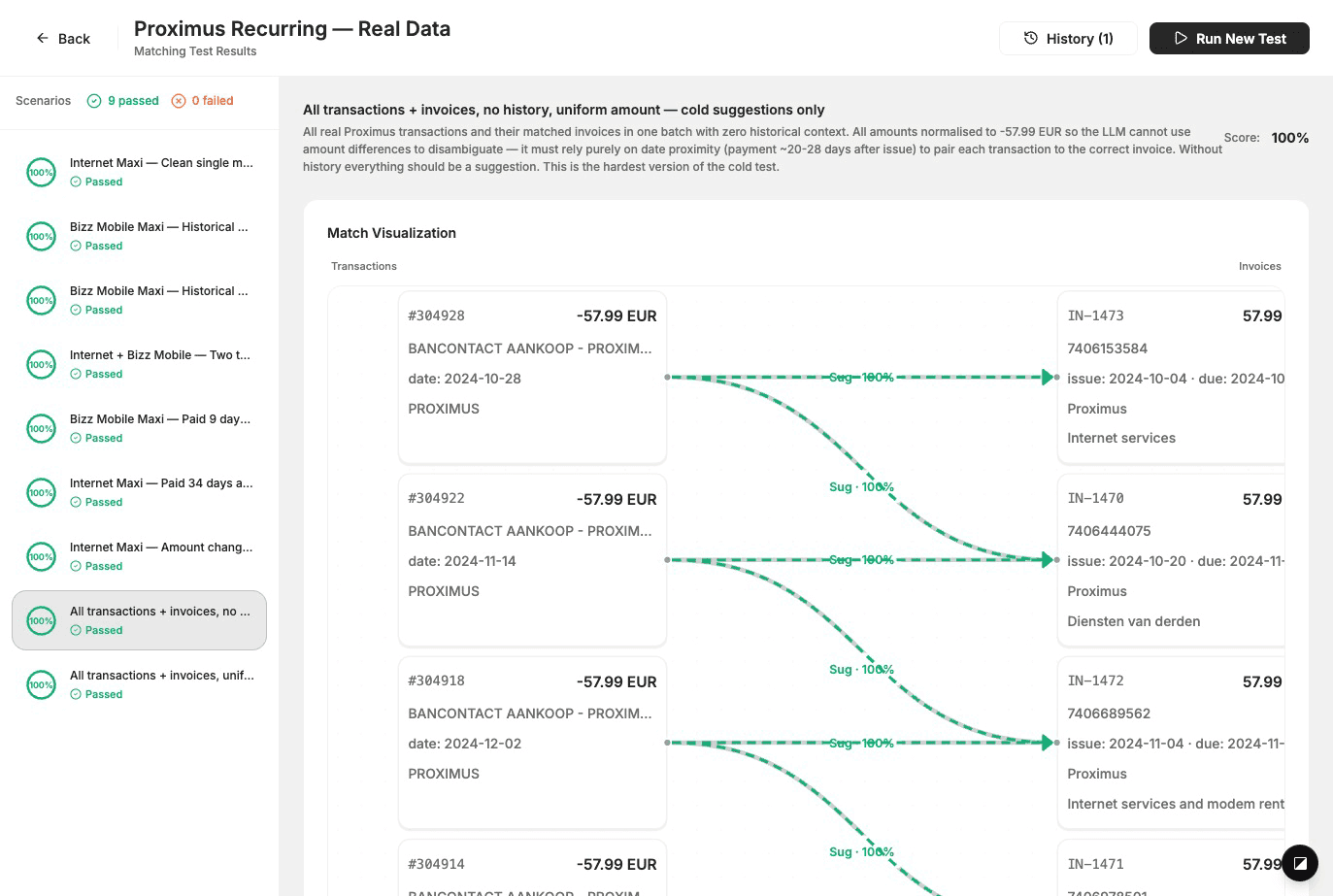
We maintain matching datasets: sets of scenarios with real-world-like transactions and invoices, plus ground truth (which pairs should be matched, and whether they’re auto-applied or suggested). We run the actual matcher on each scenario, compare output to ground truth, and score. Scenarios are built from anonymised production-like data so we test the edge cases that actually show up for customers. Every change to the matcher is validated against these datasets before it goes out. That’s how we keep quality high without exposing how we do the matching itself.
When we run a test, we see exactly how the matcher behaved on each scenario: which transaction–invoice pairs it proposed, how that compares to what we expected, and a score.
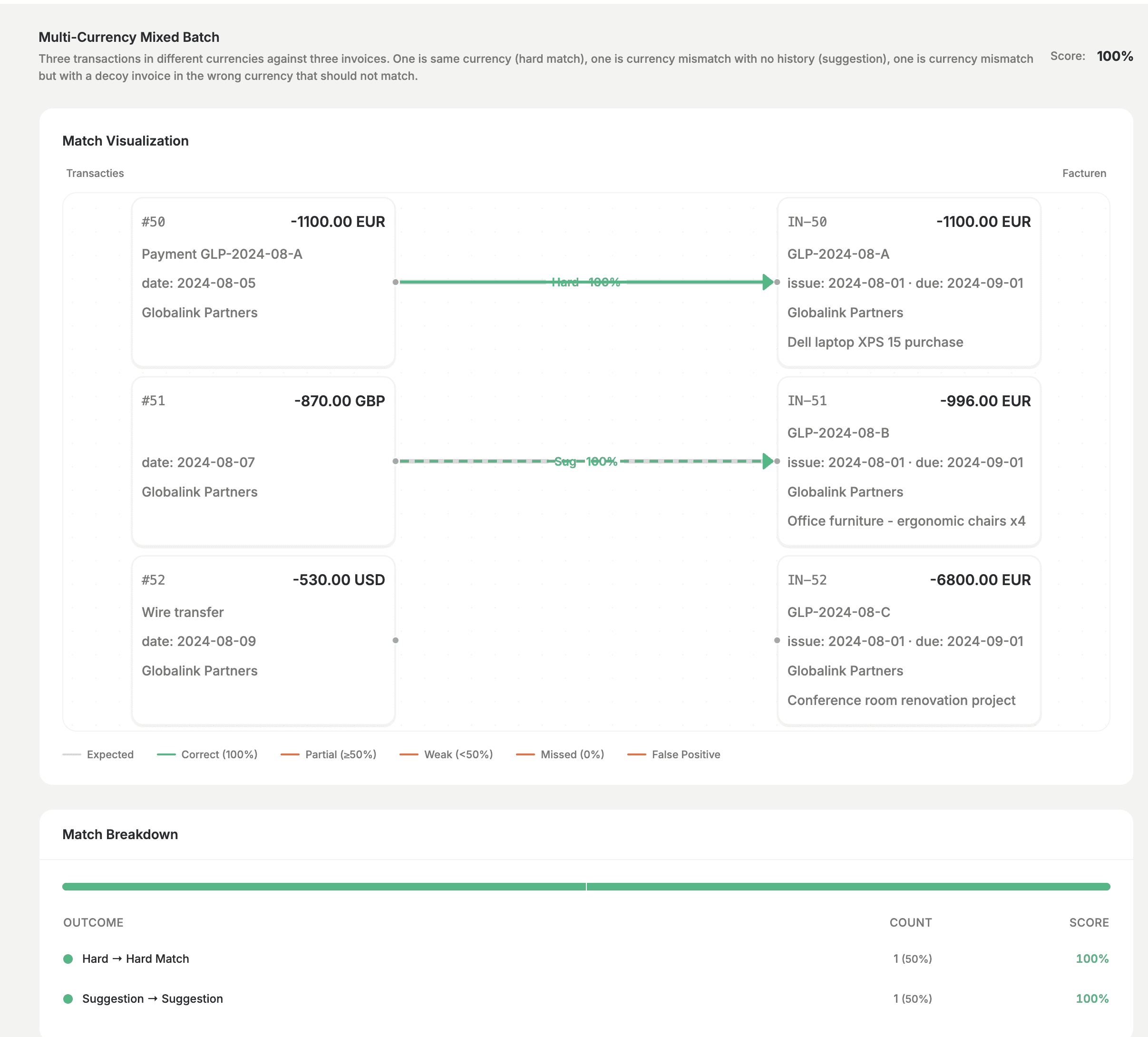
We also test trickier cases—for example multiple currencies in one batch, or situations where the model should correctly leave some transactions unmatched. Getting those right, and seeing the result in the tool, is how we avoid false positives and keep the bar high.
Why this makes us more mature
Regression safety: Before we merge a change to the matcher (or to extraction/classification), we run the relevant eval. If the run fails or the score drops, we don’t ship until we understand why and fix it.
Clear improvement criteria: We can say “this change improved the score on our matching benchmark” instead of “it feels better.”
Confidence in production: The same code path is used in eval and in production, so when we say “the matcher is evaluated,” we mean the thing that runs for customers.
Faster iteration: We can try prompt and logic changes and get a numeric result in minutes, without manually re-checking dozens of cases.
We’re not claiming we’ve solved AI evaluation in general. We’ve solved our evaluation for our pipelines: same code, curated scenarios, and a strict definition of “pass.” That’s the standard we hold ourselves to as a product that touches real accounting data.
What’s next
We keep adding scenarios to our matching (and other) datasets as we discover new edge cases in production or from support. We’re also extending the same evaluation discipline to other AI features. The goal stays the same: improve the models in a measurable way, and never ship a regression without knowing it.
If you’re building AI into critical workflows—especially in fintech or accounting, investing in your own evaluation pipeline early pays off. It’s what lets us move fast without breaking things.
— We are René Van Der Schueren and Jonathan Callewaert (CTO). We've built the Transaction Matcher at Cashfeed. In this post we share how we approached one of the most frustrating problems in finance workflows: matching invoices with bank transactions.








